Theory vs. Practice
Diagnosis is not the end, but the beginning of practice.
Critical wrk and wrk2 bugs: all wrk/wrk2 benchmarks since 2012 are bogus
Nowadays, benchmarking is not a walk in a park. As yet another coincidence, wrk and wrk2 (2012) have been created to complement weighttp (2006) and IBM AB for "Apache Benchmark" (1996)... just after we published G-WAN (ab.c, weighttp-based) ground-breaking 2011-2012 benchmarks bringing new unknown heights in an otherwise boring, infinitely self-complacent industry.
Below is the G-WAN/cache October 2025 version – tested with an heavily corrected wrk2 version renamed wrk3:
G-WAN RPS NGINX RPS G-WAN is N times faster
----- ------------------- ------------------- -----------------------
users 10s 30s 3m 30m 10s 30s 3m 30m (all 4 tests combined)
----- ------------------- ------------------- -----------------------
1 151k 142k 152k 141k 104k 103k 103k 104k 586 / 414 = 1.41 │ The G-WAN Speed
10 977k 996k 945k 927k 623k 616k 608k 601k 3.3m / 2.4m = 1.57 │ (wrk's architecture
1k 2.0m 1.9m 1.8m 1.8m 1.0m 963k 964k 956k 7.6m / 3.9m = 1.93 │ is the bottleneck)
10k 3.4m 1.8m 896k 729k 789k 729k 696k 716k 6.8m / 2.9m = 2.33 ║║║ The G-WAN MultiCore
20k 5.6m 3.7m 1.0m 713k 755k 724k 671k 682k 11.1m / 2.8m = 3.95 ║║║ Scalability (wrk's
30k 9.0m 4.2m 1.1m 723k Terminated (OOM) 15.1m / 0 = infinity ║║║ architecture is
40k 15.0m 5.8m 2.1m 723k Terminated (OOM) 23.6m / 0 = infinity ║║║ the bottleneck)
To show a preview of what's coming soon (tests made with the obviously slow wrk3 tool):
G-WAN Oct 2025 G-WAN Apr 2026 -------------- -------------- 1: 151k RPS 1: 223k RPS │ To appreciate these numbers, keep in mind that 10: 997k RPS 10: 1.4m RPS │ on the same machine NGINX tops at 1m RPS with 1k users 1k: 2.0m RPS 1k: 2.4m RPS │ before declining. 10k: 3.4m RPS 10k: 15.5m RPS │ 20k: 5.6m RPS 20k: 34.4m RPS │
- wrk2 (10-second) at 10k users: G-WAN-2025 was 453 times faster than NGINX (because wrk2 is completely bogus).
- wrk3 (10s to 30m) at 10k users: G-WAN-2025 was 2.33 times faster than NGINX, and G-WAN-2026 is 6.65 times faster.
- wrk3 (10s to 30m) at 20k users: G-WAN-2025 was 3.95 times faster than NGINX, and G-WAN-2026 is 8.70 times faster.
- wrk3 (10s to 30m) at 30k+ users: G-WAN-2025 was infinitely faster than NGINX, and G-WAN-2026 is infinitely faster.
G-WAN keeps going while NGINX has to stop, due to a lack of memory on this 192 GB RAM, Intel Core i9 PC (the wrk/2/3 tools consume 190 GB RAM at 40k users, and NGINX uses more RAM than G-WAN).
G-WAN running for 30 minutes is as fast or faster than NGINX running for 10 seconds – on all concurrencies. While letting wrk3 test 1 to 40k users, G-WAN runs marathons faster than NGINX runs 100m sprints.
So G-WAN is faster than NGINX at short, middle and long test runs, beating the market leader (with the favorite NGINX benchmark) for the 100m sprint, 5km, half and full marathon races.
And G-WAN RPS keep growing when concurrency grows, while NGINX RPS peak at 1k users and decline, proof that wrk3 is the bottleneck for G-WAN, and that NGINX is the bottleneck for wrk3.
What follows, is the why and how, and the wrk3 source code fixing 4 wrk/wrk2 major concurrency programming errors that were leading to artificially inflated scores – up to 6.1 billion RPS with G-WAN.
SUMMARY OF THE FACTS
Working on a G-WAN benchmark tool allowed me to (1) enhance the G-WAN client and server sides, (2) question the wrk/wrk2 bogus scores, and (3) evaluate by how much the event-based queue Linux kernel architecture is the bottleneck in NGINX and wrk/2/3.
Even better, instead of the G-WAN performance drop after 10k users (wrongly) reported by wrk2, now wrk3 (rightly) shows that G-WAN performance NEVER drops (G-WAN RPS grow with the number of users, which is not the case for NGINX after 1k users).
This demonstrates that wrk3 is the bottleneck for G-WAN, and that therefore my upcoming benchmarks (run using the benchmarking tool built into G-WAN) will be much (much) better than those from wrk3.
Any serious expert can confirm these points just by looking at the tests. My wrk2 source code fixes documented below also demonstrate that wrk and wrk2 cannot be trusted (due to their faulty code, their scores cannot reflect the "tested server" performances).
In 2023-2024, I first used wrk (clearly written to favor NGINX and make all others fail), which takes forever to complete benchmarks with a fast server because wrk waits for all the server replies to send new requests, so, if the server takes 10 seconds to complete the test, and wrk is 500 times slower than the server, then wrk will need 500 * 10 seconds = 5000 seconds = 1 hour 23 minutes to complete a... "10-second" test.
Late 2024, an engineer suggested the "slower but more reliable" wrk2 which stops at the specified time – instead of taking forever... and delivering extreme volatility inviting people to do cherry-picking (or warm-up, leading to the same results) – a capacity that was welcomed for NGINX (the first users of wrk) – but clearly unacceptable for G-WAN.
These 4 consecutive G-WAN wrk and wrk2 tests illustrate their erratic volatility (explained later) – and keep in mind that any "serious" benchmark tests would include many more test runs, leading to heavy warm-up (providing much higher numbers):
WRK tests:
./wrk -t10k -c10k "http://127.0.0.1:8080/100.html"
Running 10s test @ http://127.0.0.1:8080/100.html
10000 threads and 10000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 11.04ms 71.67ms 2.00s 99.23%
Req/Sec 155.65 294.40 47.14k 97.57%
49782723 requests in 10.57s, 15.35GB read
Socket errors: connect 0, read 0, write 0, timeout 5349
Requests/sec: 4711830.98 ............... 4.7 million RPS
Transfer/sec: 1.45GB
./wrk -t10k -c10k "http://127.0.0.1:8080/100.html"
Running 10s test @ http://127.0.0.1:8080/100.html
10000 threads and 10000 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 6.11ms 4.49ms 610.32ms 67.86%
Req/Sec 130.23 175.12 26.26k 93.32%
279233782 requests in 10.56s, 86.08GB read
Requests/sec: 26436985.15 ............... 26.4 million RPS, 5.61x higher!
Transfer/sec: 8.15GB
|
WRK2 tests:
./wrk2 -t1500 -c1500 -R10m "http://127.0.0.1:8080/100.html"
Running 10s test @ http://127.0.0.1:8080/100.html
1500 threads and 1500 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 3.57s 2.60s 9.95s 61.44%
Req/Sec -nan -nan 0.00 0.00%
26982293 requests in 4.38ms, 8.34GB read
Requests/sec: 6157529210.41 ............. 6.1 billion RPS, 232.91x higher!
Transfer/sec: 1.86TB
./wrk2 -t1500 -c1500 -R10m "http://127.0.0.1:8080/100.html"
Running 10s test @ http://127.0.0.1:8080/100.html
1500 threads and 1500 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 3.60s 2.58s 9.99s 61.39%
Req/Sec -nan -nan 0.00 0.00%
26810632 requests in 4.39ms, 8.29GB read
Requests/sec: 6100257565.42 ............. 6.1 billion RPS, 230.75x higher!
Transfer/sec: 1.84TB
|
There are plenty of people publishing wrk and wrk2 benchmarks for their favorite servers but I have never seen any of these servers (written in C++, C#, Go, Java, PHP, Python, Ruby, Rust, TS – but, strangely, not a single one is written in C) going even close to G-WAN's 6.1 billion RPS (as we will see, these benchmark tools have been written and chosen to produce and publish clearly bogus scores – because their authors are not shy to purposely write atrociously bogus code). Reckless hype needs tools of mass-deceit.
For the record, the latest of these wrk tests are called "HTTP-Arena" and they are made on a 64-Core AMD Ryzen Threadripper PRO 3995WX, 251 GB RAM (more RAM and twice the number of CPU Cores used in my 6.1 billion RPS G-WAN wrk2 benchmarks).
So, according to the "HTTP-Arena" criteria, G-WAN at 6.1 billion RPS is 575.47 times faster (6,157,529,210 / 21,400,000 = 287.735, and then, since they use twice more CPU Cores: 287.735 * 2 = 575.47) than their best 21.40m RPS champion (obviously written in C#). With so many Cores, they can afford to do CPU Core pinning to make sure the server and client don't use the same CPU Cores (a very good thing – I can't wait for being sponsored to do the same!).
The "HTTP-Arena" website shows benchmark scores on its front page – without disclosing which tools, how many concurrent users and what file sizes are involved in the prominently published RPS scores (which in fact are not the RPS!).
That's a new fast-growing trend where AI-generated websites (or so-called "scientific" papers) are incredibly detailed with absolutely useless data and procedures – while the most crucial information is totally absent or very well obfuscated. The goal of their authors is to impress you with their apparent correctness, unverifiable due to their gaps, erratic distribution in many obfuscated locations, size and pointless complexity rather than to inform you with concise, packed together, verifiable data and unique insights.
As a caricature of such a website, there is the source-code documentation of the wrk2 benchmark tool: this is a long and sterile paraphrase of it source code, with nice-looking SVG schemas to illustrate its logic – without ever detecting its major, unpardonable defects. The goal is to make you believe that this is a well-studied high quality tool, while if fact this is a broken tool created to deceive and rob the masses.
With "HTTP-Arena", you have to dig deep to find that the concurrency is 64 but elsewhere it is 512 (we will never know, unless we read their gigantic bash scripts... themselves using parameters to hide things even further). As a major innovation, their 'scoring' procedure explains that they don't really publish RPS, but rather a mix of metrics that raise the RPS scores according to some weather forecasts and the color of a sacrificed pigeon's guts.
So you must search and find by yourself where they have published what they call "the real RPS" (topping at 20.45m RPS). Further, their website does not disclose (or I did not find it since this information is much too well obfuscated) the static file size used for their wrk benchmarks... and we are told that the tested servers do not have to do "HTTP parsing" in these benchmarks of... HTTP servers. Amazing.
Among others, the Varnish and NGINX teams taught me that hiding the details of a benchmark is the necessary condition for "creative accounting". But the most delightful part of what the "HTTP-Arena" guys claim is "leadership" is when they so happily demonstrate that HTTP/1.1 is faster than HTTP/2 and HTTP/3 – destroying the narrative of their sponsors (tip for the non-technical readers: HTTP/2 and HTTP/3 implement "pipelining" by-design). Thank you for that "independent" confirmation folks!
Their 3 fastest servers are written in C#, Rust and Go (their sponsor must be satisfied) – and the only C++ server culminates at 1.4m RPS (10 times slower than C#, Rust and Go, obviously). When you know how these 'modern' languages are written, and have tested their runtimes CPU/RAM overheads, these claims are simply ridiculously unsustainable. This fantastic Github website has been written by... 38 contributors, many of them having chosen (understandably) to stay anonymous (if they are not also fake, AI-generated github accounts).
Last but not least, these "experts" do not disclose that wrk and wrk2 are so broken by-design that their scores have no relationship with the performance of the "tested" servers. They should have known better and then quickly switched from wrk to wrk3 since the http-arena.com domain name was registered on... 2026-03-27 (a fire-back built in reaction to my recent G-WAN benchmarks?), a mere 2 weeks before the blog post you are reading (writing their many Varnish-hosted web pages showing hundreds of wrk tests certainly took longer than a couple of weeks).
These are appointed story-tellers spreading hype, not engineers – and you will see the difference if you continue reading my blog post!
So, a year ago, in April 2025, I published new [1k-40k users] wrk2 benchmarks (G-WAN reaching 242m RPS at 10k users). But a few months later, I discovered that installing wrk2 on new machines was crashing at... 10k users.
This was odd because 10k users is the concurrency where G-WAN (at 242m RPS) is vaporizing NGINX and others (which top at less than 1m RPS at 1k users). But I did not have time to fix wrk2, and I was thinking that writting a G-WAN-based benchmark would be a much better value-proposition than fixing the slow, obscure and large code of wrk2 (5,316 lines for its code, and 1,040,136 lines for its dependencies: zlib, openSSL, LuaJIT, and HdrHistogram).
Near September 2025, I noticed that an OS update had slowed-down G-WAN from 242m RPS to 8m RPS (so I wrote the G-WAN cache to bypass a 'suddenly faulty' Linux kernel syscall – restoring G-WAN performance to 281m RPS at 10k users with wrk2 again).
I thought I was safe from this point. But in April 2026 (1 year after the G-WAN/no-cache tests, and 6 months after the G-WAN/cache tests), I have been told that:
- "G-WAN wrk2 benchmarks are not honest because they last a mere 10 seconds" (the default wrk/wrk2 duration).
Well, at the Olympic Games, a 100m sprint is as "honest" as a 42 km marathon, and nobody would dare to pretend that a sprint winner is not faster than a marathon winner... or that a runner should be disqualified when it wins both sprints and marathons!
On computers, larger test durations make server RPS (not application-dependent CPU, RAM usage) converge, due to the OS kernel becoming the bottleneck. Then, all the servers, if they are fast enough, deliver similar performance as you no longer test the server. You benchmark the OS kernel.So the interesting question is why, in a benchmark supposedly designed to differentiate the fast from the slow HTTP servers, some "experts" insist to disqualify the sprint competition... or the servers that both win the sprints and the marathons?
The ones that would benefit from such a nonsensical decision are... the slowest HTTP servers. When the "neutral experts" revert to fallacies, all discussion is vain.
- "You should use another benchmark" – the fastest suggested was an obese and asthmatic Rust 12 MB file called "Oha" (and despite being "more modern" than wrk/wrk2, "Oha" still ignores pretty thousands – readability matters folks):
oha -c 1 -z 10s -w "http://127.0.0.1:8080/100.html" Requests/sec: 85219.9506 Requests/sec: 92941.4151 --no-tui oha -c 10000 -z 10s -w "http://127.0.0.1:8080/100.html" Requests/sec: 546039.7608 Requests/sec: 581882.1891 --no-tui ----- on the top of disastrous single-core and multi-core performance, the "Oha" Rust tool ----- proudly promotes an agenda that can hardly be associated to fairness: $ oha -h "-z
Duration of application to send requests: On HTTP/1, when the duration is reached, ongoing requests are aborted and counted as "aborted due to deadline". On HTTP/2, when the duration is reached, ongoing requests are waited." As the -w switch prevents sabotaging HTTP/1, why not make it the default like for HTTP/2? Double standards.
Here again, if you use a benchmark tool that is slower than the tested server, then the server can't reply faster than the requests are sent by the client to the server. Plus, the server replies must be quickly read by the client, allowing the server to send more replies – otherwise the server is waiting for the client to cope with the replies.
In my tests, the benchmarks tools are always the bottleneck – even with the slow NGINX! Then, all servers deliver similar performance because you no longer test the server. You test the benchmark tool.
A slow benchmark is as honest as a car race with a 16 km/h (10 mph) speed limit.The financialization of the industry has promoted dysfunctional behaviors as waste and inefficiency then often became enforced to facilitate "arbitration": if everyone look the same, you can freely pick the winner you wish. That's handy for privately issued debt-money (initially a public privilege, then hijacked by a very few, with the resulting ever-growing public debt paid-back by the taxpayer) to win against merit, every single time – and especially when it shouldn't.
Then, keeping everybody at the same level of mediocrity is crucial because you can't easily disqualify a clear winner running many times faster than all others (you will have to corrupt the judges, the chronometers, sabotage/disqualify/kill the best player, etc.) which is exposing the guilty, the kind of activities that greatly increase the risk of destroying all your credibility.
So, the cheaters at the switch create government-enforced "policies" that limit what people can do (with imposed nonsensical standards, norms, regulations, certifications, capital requirements, compliance, etc.) to prevent all progress from taking place, since our very first days in school (used to format minds), and later with heavily filtered publications and tools (so that unsuspecting people stay trapped in a sterile bubble, where there's no cognitive dissonance to let them question their twisted environment).
This is why the best-funded "experts" (the ones paid a fortune to issue government reports or talk at TV shows) consistently rely to fallacies. There should be public policies to prevent such abuses and disqualify the recurring outright liars from any public/private educational, research, media, legal and judicial activities (the positions of influence where they proliferate) – because if we let this happen, the only possible outcome is our total destruction.
- "Creating many threads can take so much time that wrk2 may leave no time to the actual benchmark". The following patch was provided, where stop_at is created after start (incredibly, wrk2 creates stop_at before start, so the actual benchmark time is reduced by the time taken to create both the event-loops and threads!):
--- a/src/wrk.c
+++ b/src/wrk.c
@@ -122,7 +122,8 @@
uint64_t connections = cfg.connections / cfg.threads;
double throughput = (double)cfg.rate / cfg.threads;
- uint64_t stop_at = time_us() + (cfg.duration * 1000000);
+ uint64_t start = time_us();
+ uint64_t stop_at = start + (cfg.duration * 1000000);
for (uint64_t i = 0; i < cfg.threads; i++) {
thread *t = &threads[i];
@@ -163,7 +164,6 @@
printf(" %"PRIu64" threads and %"PRIu64" connections\n",
cfg.threads, cfg.connections);
- uint64_t start = time_us();
uint64_t complete = 0;
uint64_t bytes = 0;
errors errors = { 0 };
Wow. Here wrk2 is immensely more wrong than wrk (despite claiming to be "more correct than wrk"):
wrk (which wrk2 is based on) creates worker threads and then its main() waits for the specified benchmark duration:
uint64_t start = time_us(); // GPG: after creating scripts + event-loops + threads sleep(cfg.duration); // GPG: high RPS volatility with many threads (scheduler, context-switches) stop = 1; // GPG: tell any remaining threads to stop now (incorrect)
While technically absolutely incorrect (threads independently start and stop at different times, due to scheduling and system load main() may be late at signaling the end of the party, and threads embarqued in event-queues will certainly be late at noticing it), the wrk code is much less wrong than what wrk2 felt the urge to do in a massively worse manner.
But wrk and wrk2, despite being well-promoted and widely praised, are not exactly what I would call champions:
Depending on the memory footprint of the tested HTTP server, the Linux kernel OOM (Out of Memory) kill-switch "Terminates" the benchmark tools wrk/2/3 for using 190+ GB at 30-40k users on my 192 GB RAM machine.
In contrast, G-WAN, which is doing many more things than wrk2, consumes around 386 MB of RAM at 40k users (a client being simpler than a server, this fact alone is revealing about how much expertise and care is dedicated to benchmark tools by the best-funded "scalability and benchmark experts"):
G-WAN/cache starting memory footprint: 1.7 MB (with www storing 745 files, 171 MB)
./gwan -p - running 'gwan[*]' process(es) (use 'sudo ./gwan -p' if pathnames are missing): PID PPID THRDS %CPU VIRT RSS SHRD EXE 338766 4565 2 0.0 25.0 MB 1.7 MB 0.0 KB /home/gwan/gwan :8080
G-WAN/cache ending memory footprint: 386 MB (with www storing 745 files, 171 MB)
./gwan -p - running 'gwan[*]' process(es) (use 'sudo ./gwan -p' if pathnames are missing): PID PPID THRDS %CPU VIRT RSS SHRD EXE 338766 4565 40001 376.8 3.7 GB 386.9 MB 0.0 KB /home/gwan/gwan :8080
That's why I felt the need to make my own benchmark tool, which will be integrated to and published with G-WAN. With it, it will be possible to benchmark high-concurrencies on miniPCs with 4 GB of RAM. A much (much) welcome change for the unfunded crowds in a world with ever-raising acquisition and operating costs (hardware, energy, floor-space. etc.).
Nevertheless, having promised to investigate the wrk2 issue further, I have discovered that the situation was much worse than presented, as the proposed patch simply ignored the elephant in the corridor:
(1) wrk2's thread calibration takes as much time as the benchmark itself (default for both: 10 seconds – the benchmark duration can be specified on the command-line... but the calibration duration is silently extended: calibrate_delay = 10_seconds + (thread->connections * 5), a total nonsense for all concurrencies, carefully hidden with MACROS stored in a dedicated file!).
(2) wrk2's main() setups a stop_at time before creating the threads and a start time after creating and calibrating the threads, so the benchmark_effective_duration = benchmark_specified_duration - calibration_duration
(what could possibly go wrong in wonderland, right?). Note: after some years wrk has ditched calibration, but not wrk2.
(3) wrk2's main() does the RPS calculation req_per_s = complete / runtime_s which turns the division into a multiplication (leading to bogus RPS values) when the actual benchmark time (default: 10 seconds) is reduced by the calibration time (default: 10 seconds) to less than 1 second (a textbook parallelization bug, not something accidentally done by experts).
This deadly issue happens most of the time because the calibration time and actual benchmarking time are nearly identical!
The obvious fix was to do this in wrk.c, not in main() but rather in the threads' function (both for wrk and wrk2):
thread->start = time_us(); thread->stop_at = thread->start + (cfg.duration * 1e6); // GPG: <= THE FIX aeMain(loop); // GPG: => the actual benchmark starts here, AFTER thread calibration was done
Now, we tell every thread to run for (at least) the user-specified time. wrk2 benchmarks will last longer than before because the thread calibration time will not be subtracted from the thread benchmarking execution time (they will be cumulated).
In real life, not all client threads will start and end at the same time, making benchmarks last even longer (than the default duration, or the one specified on the command-line). Also, the fairy tale of wrk/2 claiming to measure server latencies is a scam since the wrk/2 clients are massively slower than any decent server, with thousands of CPU-starved "ready" connections queued into events loops and waiting for their turn to get some attention.
This by-design issue generates yet another "Head of Line" (HoL) problem, especially with slow requests (databases, sub-requests, dynamic contents) because 1 single slow request will halt the progress of the events-queue processing for quite a while (hence the use of more client connections dedicated to these tasks, in a vain attempt to avoid blocking all the other "ready" connections for too long).
It's crazy how bad architectural choices (here events-based queues) cumulate detrimental consequences that themselves generate more complexity leading to more bad choices (ie: FastCGI) like if ever-growing madness was the only pursued goal. G-WAN did not attempt to resolve this mess, it has avoided it, hence its much higher scalability (especially for dynamic contents).
But since the starting time and execution time are different for each thread, we can't calculate the RPS in main() like wrk and wrk2 (actually wrk2 was doing much worse by interverting start and stop) are doing it since 2012: by taking the start of the first thread and the end of the last one (yet another unpardonable parallelization bug).
This is necessarily false (due to the OS tasks scheduling and background processes, all worker threads are independent, they do not start and stop at the same time, nor they have the same lifespan) – that's basic parallelism synchronization, a discipline normalized with the 1995 POSIX threads publication. In 2026, 30 years later, there is no excuse for doing it wrong... in a tool supposedly benchmarking high-performance multi-threaded servers!
Instead, the RPS must be accounted for in each thread – which in turn will contribute to report the final server performance (in RPS) a more accurately since all the thread execution durations are more exactly matching the specified benchmark time (yet the overhead of the wrk/2/3 architecture remains, so (1) it reports its own latencies rather than the servers', and (2) is the bottleneck with G-WAN):
thread->start = time_us(); thread->stop_at = thread->start + (cfg.duration * 1e6); // GPG: <= THE FIX aeMain(loop); // GPG: => the actual benchmark starts here, AFTER thread calibration was done thread->stop_at = time_us(); // GPG: save the REAL (not planned) thread exit time
Now, to understand what's next, a distinction must be done between the wall clock and the thread CPU time: the former is what you see on the office clock, and the latter is the amount of CPU time given by the OS scheduler to each thread (getting time slices to emulate parallelism on non-realtime OSes, where many more programs run than available CPUs or Cores).
IF (1) the number of threads is inferior or equal to the number of CPU Cores, (2) the system is only running the benchmark tool and the tested server, (3) each thread is pinned to a different CPU Core, and (4) threads don't share resources requiring locks or CPU cache reloads, THEN each thread should execute in parallel, and get the same mount of CPU time than indicated by the wall clock. In theory, it's just like if you had as many computers as you have CPU Cores.
In practice, modern Desktop and server OSes are not real-time OSes and they run many tasks in the background, rather than just the benchmark tool and the tested server. As a result, even with the 4 code/design conditions listed above, some threads will get deprived from CPU time and will perform worse than other, more lucky, threads.
And if only some or none of the ideal conditions described above exist, then the CPU time allocated to each thread is reduced immensely to the point where –for the badly designed programs– you cannot reasonably predict the outcomes (in the charts below, in green, SLIMalloc is the only memory allocator to be constant, whatever the system load):

The 2007 Ebizzy benchmark shown in the above charts has been written and documented by Intel Corp. (a CPU vendor):
"Ebizzy is designed to replicate a common web search application server workload. A lot of search applications have the basic pattern:
The interesting parts of this workload are:
- large working set,
- data alloc/copy/free cycle,
- unpredictable data access patterns.
The records per second should be as high as possible, and the system time as low as possible."
Over the years, Intel Ebizzy has been considered so relevant that it has been included in:
"The Linux Test Project, a joint project started by SGI, developed and maintained by IBM, Cisco, Fujitsu, SUSE, Red Hat and others, has a goal to deliver test suites to the open source community that validate the reliability, robustness, and stability of Linux."
So what we have in the above charts, is the demonstration that the most advanced memory allocators (written by the best-funded companies in the History of capitalism) are... killing the "performance, reliability, robustness, and stability" of Ebizzy... and anything else allocating and freeing memory, whatever the OS.
How is it possible for SLIMalloc to do so much better? Even with the last 2 charts (with heavy erratic background tasks), SLIMalloc is obviously slower than with a system not running background tasks – but SLIMalloc is the only one able to keep a constant execution time.
Why? How? That's a conjunction of the good multi-thread programming practices (listed above in the highlighted IF/THEN) and a low computational overhead so that each CPU time slice given by the OS scheduler to SLIMalloc (or G-WAN) benefits more to it than to its (unfortunate, badly-designed) competitors.
In all the History of Computer Science, SLIMalloc is the only censored memory allocator (probably for threatening strategic GAFAM powers... like selling to governments all over the planet the backdoors they have injected in their own OS, standard protocols, and Web browsers), all tested in colored charts: GNU LibC, Google, Microsoft, Facebook, pre-allocated, and SLIMalloc (the fastest and yet the only one featuring "memory-safety", an unprecedented threat against 70 to 90% of all vulnerabilities, according to the NSA).
On the top of a poor design, Facebook (in pink in the charts) cheats: jemalloc tries to look "faster" and much less "erratic" than it is in reality by releasing only half of its allocated memory (look at the vertical position of its line-ending circle in the first series of charts published above, and at the pink arrow in the chart below):
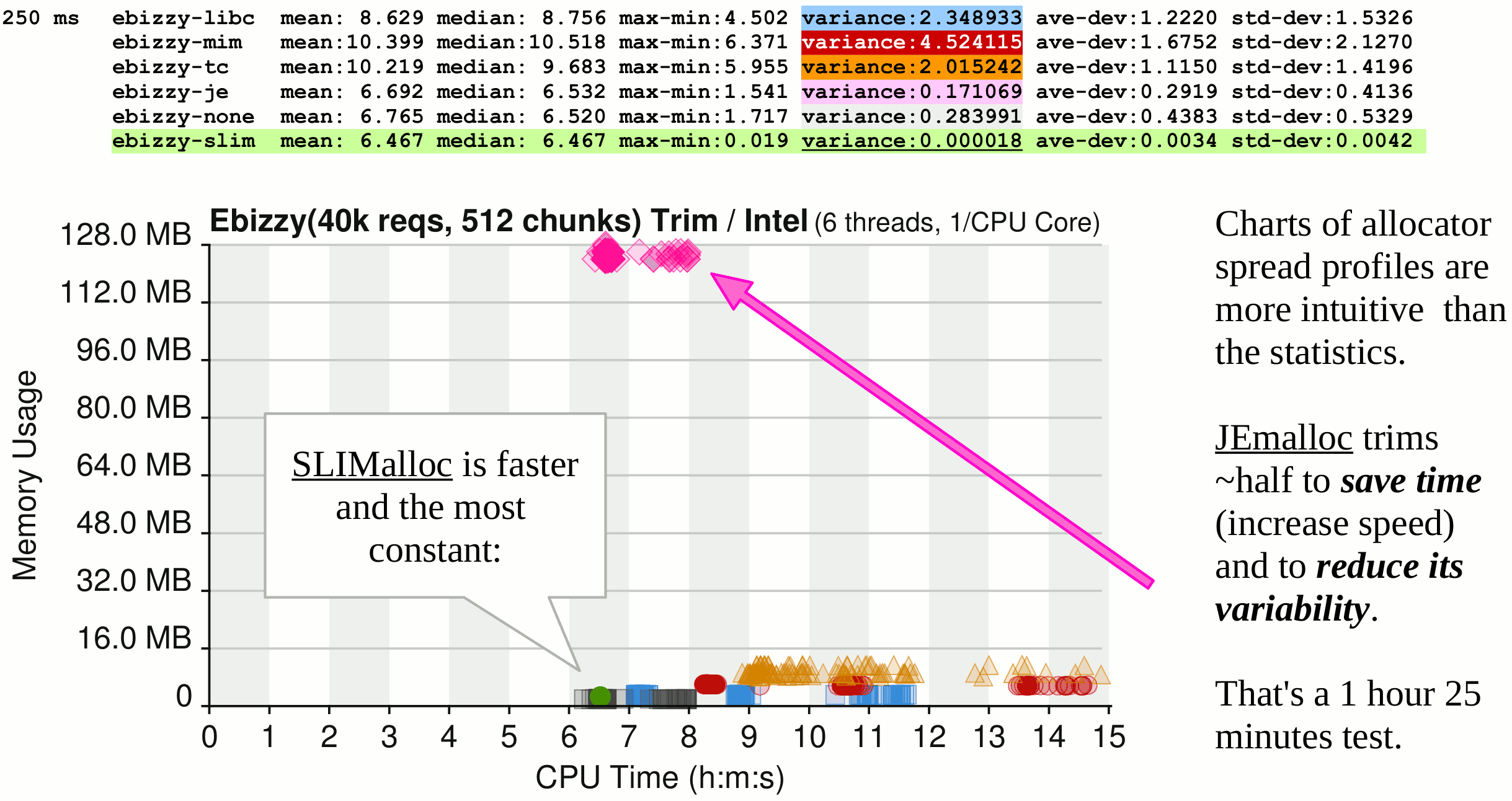
Doing the job by half helped Facebook to pretend that jemalloc was really fast – and its non-released memory does not have to be re-allocated later (so that's a double-win based on... treachery – the only way for some among us to exist).
The purpose of this SLIMalloc paper was not to shame the GAFAM about their poor performance, nor about their lack of useful and reliable features, nor even about the fact that the 3 decades-old GNU LibC was actually safer than all the "more modern" GAFAM memory allocators, but rather to demonstrate that a memory allocator can be both fast, fully-featured and yet deliver "memory-safety" to all Apps, libraries and the OS.
In a sane world, the GAFAM should have purchased a SLIMalloc source code license – but they have preferred to censor SLIMalloc (ACM.org, Stackoverflow, Wikipedia, LinkedIn, DARPA, etc.). Like for Remote-Anything (RA), Global-WAN, Global-WET, and G-WAN, the ones occupying all the space are thin-skinned, glorious, infinitely-funded cheaters using State-powers to furiously censor anyone doing better than them.
And, guess what, wrk/wrk2 enjoy none of these necessary refinements, hence the highly volatile execution times and "measured by an elite client tool" bogus RPS and latencies (that actually reveal the client defects, when it is slower than the tested server). Inheriting its architecture from its predecessors, even wrk3 is slow (to the point of being the bottleneck with G-WAN), but at least it reports correctly its own client performance (deceptively presented by the wrk/2 authors as the server RPS and latencies).
So, even before testing the new, "thread-lifespan patched" wrk3 we can tell that it will now show, both for G-WAN and NGINX:
- higher RPS for low concurrencies, because the wall clock is almost equal to the CPU time allocated to each thread for the benchmark (unless you start heavy programs like video transcoding during the benchmark).
- lower RPS for high concurrencies, because the wall clock is larger than the productive CPU time given to benchmark threads (due to the overhead of the OS scheduler, context-switches, syscalls, locks, event-queues latencies, etc. making threads get less productive CPU time, that is, time slices, than the wall clock delay should allow)... hence non-linear performance with growing concurrencies (unless we have plenty of CPU Cores to reduce the scheduling overhead).
Add the many bottlenecks introduced by the wrk/2/3 architecture and you can understand why the performance are not linear with the number of involved threads, even when they are inferior or equal to the number of CPU Cores (and even when testing a fast and scalable server like G-WAN).
Proof: with wrk3 G-WAN RPS grow with the concurrencies (while, past 1k users, the opposite is true for NGINX).
After having modified wrk2 to do this properly... wrk2 has reported even more bogus threads benchmark lifespans, incorrectly claiming that G-WAN delivers 469m RPS at 10k users. How is this possible?
(4) Unfortunately, wrk2 has added to wrk yet another deadly issue: it stops the thread workers far before the planned time, and for no obvious reason. The potential reasons are multiple: broken connections, event loops errors, signals, and even more bugs in all of these organs (hence, probably, the loss of options for end-users trying to make sense out of the resulting incoherence).
This explains the erratic performance, and the "elegant bypass" of the author (who decided to bury the problem rather than to resolve it, by picking out of his hat, as seen previously, a nonsensical threads lifespan from main() without consideration for the thread calibration process overhead), generating the dire consequences exposed below in all of their splendor:
./wrk2 -d10s -t3 -c3 -R100m "http://127.0.0.1:8080/100.html" Created 3 event-loop(s) in 0.000 seconds Created 3 thread(s) in 0.000 seconds Running 10s test @ http://127.0.0.1:8080/100.html 3 threads and 3 connections - thread #? PLANNED start: 1,776,343,474.613 sec, stop:1,776,343,484.613 sec, duration:10.000 sec, cfg.dur:10 - thread #? PLANNED start: 1,776,343,474.613 sec, stop:1,776,343,484.613 sec, duration:10.000 sec, cfg.dur:10 - thread #? PLANNED start: 1,776,343,474.613 sec, stop:1,776,343,484.613 sec, duration:10.000 sec, cfg.dur:10 - thread #0 benchmark time: 0.018 sec (18,200 usec) - thread #1 benchmark time: 0.029 sec (29,228 usec) - thread #2 benchmark time: 0.034 sec (34,120 usec)
Note that this 4rth wrk2 bug is shown here with a mere 3 threads. It means that every wrk2 reported RPS are wrong. Maybe less visibly wrong than with more threads, but clearly based on by-design incorrectly-calculated thread lifespans (so all the wrk2 tests ever made since 2012 are totally wrong: they don't have any relationship with the actual performance of the "measured server", the only involved criteria is by how much the division became a multiplication – preventing overflows is a basic programming skill).
There's no more wonder about why the wrk2 results may be nonsensical (even after our previous much-needed patches!): a benchmark supposedly lasting 10 seconds (or 10 minutes) is erroneously reported as stopping far before the worker threads have been running for 1 second... turning the RPS division into a multiplication: req_per_s = complete / runtime_s;
This generates nonsense, and the widely celebrated bogus wrk2 reports that G-WAN delivers... 6.1 billion RPS:
./wrk2 -t1500 -c1500 -R10m "http://127.0.0.1:8080/100.html"
Running 10s test @ http://127.0.0.1:8080/100.html
1500 threads and 1500 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 3.57s 2.60s 9.95s 61.44%
Req/Sec -nan -nan 0.00 0.00%
26982293 requests in 4.38ms, 8.34GB read
Requests/sec: 6157529210.41 (6,157,529,210.41)
Transfer/sec: 1.86TB
|
./wrk2 -t1500 -c1500 -R10m "http://127.0.0.1:8080/100.html"
Running 10s test @ http://127.0.0.1:8080/100.html
1500 threads and 1500 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 3.60s 2.58s 9.99s 61.39%
Req/Sec -nan -nan 0.00 0.00%
26810632 requests in 4.39ms, 8.29GB read
Requests/sec: 6100257565.42 (6,100,257,565.42)
Transfer/sec: 1.84TB
|
Now comes the real problem, because what we see here should have never, ever happened. Something is deeply broken, somewhere, in that horrible mess of 5,316 lines of code called wrk2 (assuming that its gigantic dependencies, of over 1m lines of code, are not involved in the problem).
Your mission, if you accept it, is to find it (well, nobody has ever done this in the past 14 years) – not even the wrk2 author, nor the team of 17 persons(!) handling wrk2 bugs and incidents (75 so far) on github with 421 forks and 4.6k stars.
The bogus wrk has 3k forks, 40.3k stars and 146 incidents and is only supported by Will Glozer... part of the wrk2 github team!
The development documentation of wrk2 is incredibly detailed on tens of Web pages, with SVG schemas and code comments – yet, while conducting this impressively large code analysis, nobody (whether humans or AI bots) has detected its completely broken way to measure both the server performance and latencies (its only purpose).
That's quite a lot of promotional efforts (aka "reputation building") for such a broken by-design tool. Like if the underlying message was: "that's rock-solid Science, peer-reviewed and validated by top-notch specialists that have spent more time on it than you can afford to dedicate to the task. Move on, there's nothing of value you can bring to the matter. 200% sure!"
I am not paid by anyone. My products, technologies and papers are censored for 3 decades by the friends of the above geniuses. Yet I have done the work that they failed to do – for their own benchmark tools. And I have documented the guilty: after fixing the first 3 bugs, disabling the defective organ (presented as a "major achievement", a recurring pattern it seems) finally resolves the problem:
//aeCreateTimeEvent(loop, calibrate_delay, calibrate, thread, NULL); // GPG: disable calibration aeCreateTimeEvent(loop, timeout_delay, check_timeouts, thread, NULL);
The tiny threads lifespan issue is resolved (remember, I setup and check all thread benchmark time from within each thread):
./wrk2 -d10s -t3 -c3 -R100m "http://127.0.0.1:8080/100.html" Created 3 event-loop(s) in 0.000 seconds Created 3 thread(s) in 0.000 seconds Running 10s test @ http://127.0.0.1:8080/100.html 10 threads and 10 connections - thread #? PLANNED start: 1,776,344,751.151 sec, stop:1,776,344,761.151 sec, duration:10.000 sec, cfg.dur:10 - thread #? PLANNED start: 1,776,344,751.151 sec, stop:1,776,344,761.151 sec, duration:10.000 sec, cfg.dur:10 - thread #? PLANNED start: 1,776,344,751.151 sec, stop:1,776,344,761.151 sec, duration:10.000 sec, cfg.dur:10 - thread #? ACTUAL STOP: 1,776,344,761.151 sec, thread lifespan: 10.000 sec - thread #? ACTUAL STOP: 1,776,344,761.151 sec, thread lifespan: 10.000 sec - thread #? ACTUAL STOP: 1,776,344,761.151 sec, thread lifespan: 10.000 sec - thread #0 benchmark time: 10.000 sec (10,000,005 usec) - thread #1 benchmark time: 10.000 sec (10,000,006 usec) - thread #2 benchmark time: 10.000 sec (10,000,004 usec)
See? By removing the "Crown Jewels" of wrk2 (its pointless and broken yet celebrated calibration)... and fixing its 3 other deadly bugs, you get back an usable tool. The advantage of using wrk2 is that it stops, more or less at the specified time, instead of taking forever to complete the benchmark, like wrk does it (when it is slower than the tested HTTP server).

|
wrk2 has been first published in 2012 by Gil Tene (Bachelor of Science from the Technion Israel Institute of Technology, CEO and then CTO at Azul Systems which markets a "Mission-Critical Java Application Server", with 12 ResearchGate publications – including a 2005 US patent US8949583B1 titled... "Concurrent atomic execution"). In 2026, Gil Tene's wrk2 4 unpardonable, basic concurrency programming errors are 14-year old – for something actively promoted by all the public/private ecosystem and proudly presented by Gil Tene as "A constant throughput, correct latency recording variant of wrk". |
Yet, wrk, created in 2012 by Will Glozer, "only" miscalculates the RPS by 3 orders of magnitude, and has removed its calibration worsening its (still there) benchmark time flaw. wrk's remaining gap, beyond its bogus execution time and its slow architecture, is about not stopping at the specified time when a server (like G-WAN) is faster than the benchmark tool – something that some may have interpreted as a G-WAN flaw: "Oh, you see, this server is so slow that the test lasts forever!" while actually the opposite was true: wrk/2/3 are slow, not G-WAN (hence, most probably, its constant censorship since 2009).
So it would be very interesting to hear about why Gil Tene felt the need to introduce 4 major bugs with his (so badly designed) threads calibration time in wrk2 (increasing the bogus wrk RPS errors by 2 additional orders of magniture with the latest version of G-WAN), to the point where it completely defeats the purpose of benchmarking... while claiming that wrk2 is "more exact" than wrk!
After examining the wrk2 source code, there are very (very) strange things like variables and functions implemented and not used, redundant slow function calls, and... purposedly misleading messages like "Initialised %d threads in %.3f ms" while the timing was for event-loops creation (thread creation was not timed and was not reported) – here we don't talk about a skills gap: fairness is absent, for decades (and in million people rather than just the wrk2 author).
The source code of wrk2 would deserve a complete rewrite (if it was not so badly designed in the first place). Its only purpose seems to be as slow, faulty and inefficient as possible via unpardonable elementary thread-synchronization programming mistakes (to slow-down fast servers)... while carefully hiding its sins with pointless layers, redundancy, chaos and complexity (like in "a haystack is required to hide a needle")... and eventually boosting the benchmark scores (to incoherent summits when pushed to its limits).
Despite their so obvious flaws, wrk and wrk2 are cited and used in thousands of academic papers, by the researchers of the best universities – like if these public-sector "experts" were unable to detect and find the abominable programming errors of these benchmark tools – or maybe because that's a community issue, where unconditionally rubbing the back of other community members is the only way to be accepted by that community.
Seeing that, the taxpayer may wonder why he works to pay armies of incompetent and corrupt public-sector cheerleaders (of broken by-design tools made by well-funded private sector impostors) that enjoy nice wages, dedicated heated and cooled buildings, individual offices, parking places, equipment, energy, conferences, trips, papers and patents funding, and guaranteed retirements.
What they do is much more reckless marketing than "Science" – and the world does not need government-appointed lies.
More generally, using event-queues for high-latency networks, low concurrencies and mostly-idle clients works (slowly, worsening the network latencies), but this model will quickly show its limits on localhost (or on fast networks), and generates VERY HIGH latencies ("ready" queued connections are CPU-starved since only one is processed at a time), while higher concurrencies (more users) will hit the small 2-second wrk2 timeouts (yet another by-design benchmark tool issue):
#define SOCKET_TIMEOUT_MS 60000 // GPG: 1 minute, was 2000 (2 seconds) #define TIMEOUT_INTERVAL_MS 60000 // GPG: 1 minute, was 2000 (2 seconds)
The "queue" concept itself intuitively means that an extra delay (due to extra work) is injected for each event. Computers go faster when doing less work, not more work. The only reason why we have OS queues is because this allows to do "syscalls batching" (that is, reducing the usermode-kernel transition costs)... since someone wanted to stay 100% in charge of the protected-mode OS kernel, drivers, observability, etc. A micro-kernel would have made things immensely simpler and more efficient (fostering a free and open competition, and sparing the need for all these kernel-bypass experiments...).
Today, we have systems with asynchronous, batched, or exception-less syscalls – to substantially reduce the overheads associated with frequent kernel transitions (involing administratively self-inflicted, technically-pointless context switches and data copies). POSIX OSes now support zero-copy through page remapping and copy-on-write... while this can be done in a trivial, much simpler, cooperative, zero-copy way between the network stack and the application (by merely passing pointers to packet buffers).
See how ridiculous complexity – and the financial and computational costs it involves – are ever-growing?
It's like if this industry makes things more inefficient to resolve more problems that should have never existed in the first place.
Worse than the artificially injected slow down, all the servers (Apache, NGINX, LiteSpeed, etc.) using event-queues use a FIXED (in their configuration files) number of threads/processes (workers) and per-thread/process queue-length (worker connections) – leading to the impossibility for these servers to adapt to the traffic size.
Either you set a low number of workers and worker_connections to limit the queue size and the latencies it generates (and your server will be unable to accept more concurrent connections than defined in the configuration file), or you set a large number of workers and worker_connections to scale (up to the new configured limit)... at the cost of even higher latencies and therefore much lower RPS (on the top of never be able to release RAM and enjoy lower latencies when a traffic peak ends) !
G-WAN does not have all of these problems, because it does not use a FIXED configuration, nor queues: instead, G-WAN starts small and grows/shrinks its workers as needed, to scale with the network traffic.
Of course, even G-WAN has a limit – but it is related to the CPU, RAM and OS kernel's hardcoded limits, internal structures, lists, and TCP/IP stack – not to your configuration files.
And the G-WAN limit is (1) it is much higher than the one of the event-based servers, so (2) you benefit at all times from the lowest possible RAM and CPU usage and latencies, and (3) therefore can enjoy optimal RPS.
Last but not least, the calibration disaster should have been made optional by its author – at least, without it, the wrk2 bugs would have been easier to find and fix, and wrk2 would have been useful (instead of a major nuisance, for myriads of end-users, during decades, all over the world).
Either the wrk/2 authors, these "widely praised scalability experts" that fill and get parasitic patents about concurrency (paraphrasing the R&D of others is not innovation) and the github projects likers, forkers, support teams, and academic cheerleaders are not familiar with the concept of multi-threading, arithmetic overflow and compiler warnings... or they knew very well what they were doing.
In both cases, their tools, products, research and papers are not trustworthy – and the fact that nobody has felt the need to correct them (in 14 years, despite a wrk2 dedicated team of 17!) reveals how serious is the whole self-congratulating cohort... so honest that it feels the need to censor, denigrate and sabotage anyone doing better.
Apache, NGINX, wrk and wrk2 are cited by thousands of academic papers, but there's not a single citation for SLIMalloc (resolving the "memory-safety" issue that two consecutive US Presidents publicly called a solution for) or G-WAN – despite having displaced all other servers since 2009. These double standards explain a lot of things, and why the US and European economies are in free fall.
I have quickly corrected the most deadly bugs, added some useful comments and printed messages, added pretty thousands for the readability of RPS and timing, a crash handler to show where and why the animal fails, etc. – but I don't see the point of wasting more time on the outrageously amateurish wrk2 codebase. Stating "amateurish" is much nicer than "criminal" because there are many hints that all this mediocrity and bad design choices were planned rather than merely due to utter incompetence: one cannot at the same time do difficult things and fail miserably on the most basic things... that are critical for the whole to operate correctly.
So much for the "plausible deniability" too often presented as an excuse by the serial wrongdoers: "don't attribute to maliciousness what can be attributed to stupidity". Yes, right. Strangely, the "stupid guys" are reaping the bounty every single time, by censoring, denigrating and sabotaging anyone doing better... and they only make mistakes that actually benefit them. Stupidity is supposedly enjoying a more random distribution than unleashed greed enjoying infinite impunity.
Reminder: wrk was clearly written with several bias that favor NGINX and all slow servers – while artificially slowing-down the fast servers. wrk2 enthusiastically went even further in the promotion of NGINX (and the Gil Tene Java App. Server) by injecting 4 unpardonable multi-threading errors. G-WAN, while faster than all others since 2009 (and supporting 18 programming languages – including Java), was constantly censored, denigrated and sabotaged by two well-funded (closed-source and open-source) Operating Systems and their minions.
On one side, there's relentless funding and promotion, and on the other side, 18 years of constant sabotage for G-WAN, and 28 years for TWD. Call this "accidental" if you can.
SO, SINCE 2012 MOST WRK AND WRK2 BENCHMARKS ARE BOGUS – AND NOBODY HAS EVER NOTICED... IN 14 YEARS!
SO MUCH FOR THE "MANY EYES" PROTECTING OPEN-SOURCE USERS FROM SCAMS AND VULNERABILITIES.
After fixing wrk2's latest available source code and recompiling it, I quickly tested it and... it crashed at 10k users. Wow, nobody seemed to have addressed the crash I have experienced a year ago.
I re-downloaded wrk2 from several sources to compare it to the version I downloaded in October 2024. In the 2024 source code, the RPS flaws were already there... but at least the 2024 version (published just before my G-WAN and NGINX April 2025 G-WAN benchmarks) has no problem to test up to 40k users without crashing.
In the newest versions of wrk2 available on Github, Ubuntu repositories, etc., the Makefile has also been heavily rewritten (so they have time for this, but not to make better tools, or to correct the faulty ones they distribute). The resulting executable file does not embed the libraries it relies on, so the executable will fail if copied to another machine, due to GNU LibC incompatibilities and shared library versioning – and all these new versions crash at... 10k users! Cui bono?
If someone wanted to sabotage the tool that has allowed G-WAN (or any reasonnably performing server) to shine (and that has revealed the deffects of NGINX and all other servers), the exact same thing would have been required to be done... and it was done, by everyone at the same time, as if sabotaging wrk2 even further was a global urgency (a cover-up?).
But an even larger damage was caused by wrk/2: sabotaging the instruments of measure prevents researchers and developers from finding if they make progress, hosting and Cloud customers from evaluating the resource they pay for, and end-users from choosing an efficient HTTP server. It is reminiscent of the damage purposely caused by the debasement of currencies, fake Science (eg: the "climate apocalypse" has been retracted by the IPCC – unlike the unjustified "carbon tax" and the nonsensical war against the CO2, now proven as uncorrelated to temperatures and mankind[ 1 , 2 , 3 ]), and ever-larger new malformed programming languages that are much slower, more unsafe, and increasingly more complex than the C language used to create all of them:
• Rust (14 years, since 2012) 33 CVE records ( 2.36 per year, "memory-safe" language) • Go (17 years, since 2009) 339 CVE records ( 19.94 per year, "memory-safe" language) • .NET (24 years, since 2002) 5,433 CVE records (226.37 per year, "memory-safe" language) • Javascript (31 years, since 1995) 8,587 CVE records (277.00 per year, "memory-safe" language) • Java (31 years, since 1995) 3,781 CVE records (121.96 per year, "memory-safe" language) • GLibC (39 years, since 1987) 224 CVE records ( 5.74 per year, "memory-UNsafe" language)
The C language would be much safer than the Rust language had it adopted SLIMalloc censored by the U.S. DARPA. Using taxpayers' money to destroy the capacity of the whole planet to evaluate things, to think correctly, to experiment, to understand the foundational concepts of a technical matter, is a crime – not an improvement.
As we have seen, the use and abuse of double standards are a constant in this industry dominated by serial criminals:
Google, the most prominent search engine, was violating its own internal policies (and the rule of law) by selling our brands (company and products names), as keywords to its customers paying Google to place advertisements... redirecting users clicking search-engine links stating "Buy TWD Remote-Anything" to the websites of our well-funded (but technically inferior) competitors.
We have had to change 6 times of e-commerce platform – after they were purchased, one after another, by Digital River, the then dominant player of the online payments industry – which then has systematically redirected our products buyers to our... honorable competitors.
Our domain names have been hijacked by Verisign and DnsMadeEasy during 3 months, a coordinated action that was feeding click farms... you guess it, promoting our honorable competitors.
Our symmetric and redundant MCI-Worldcom leased lines (24/365 SLA) have been broken 3-4 times a week for more than 4 hours each time during months, until we reverted to servers hosted by third-parties (often shadow-banning, exposing and sabotaging their own hosted servers).
RA and G-WAN under Windows, but also G-WAN under Linux, have been the target of OS updates modifying the C standard library to disable features or make our products crash (this is why G-WAN has now ditched the GNU LibC). In 2025, Linux went a step further by sabotaging a kernel syscall to reduce the G-WAN performance by a factor 30 (this was resolved by implementing the G-WAN cache, to limit the use of this suddenly defective syscall).
More than EUR 1.2B of TWD assets have been stolen by a bank, an insurance and a government – and providing official evidence of the collusion of the three incriminated parties to the related capital's general prosecutor has only triggered assassination attempts, making me relocate before finding if the 4th attempt would be successful.
Licensing agreements for Global-WAN.com (securing the standards by encapsulating them in unconditional security) have been (illegally) blocked in a coordinated manner by the authorities of several countries.
Global-WET.com (resolving the energy costs and scarcity, a global issue which receives continuous funding for more than a century without ever delivering workable solutions), presented at the 2019 Munich Security Conference, has never been promoted or funded (while many other participants received hundreds of million euros, some billion euros... to deliver nothing at all, nothing new, or nothing useful).
Invariably, tribunals have removed all officially-collected incriminating evidence from the investigation files to then decline to forbid or punish these decades-long anti-competitive practices and robberies. "Justice", right? Or rather the opposite of it. This inversion of reality is a foundational principle for some among us. They define themselves as having the right to pretend to do good, and then purposely do bad – for the sacred goal of robbing all others... with the blessing of many governments, which are their instrument, mere toys in their hands.
Add unlimited funding, promotion and tax/legal leniency for some, and merciless censorship, sabotage and denigration for all others, and you can understand how a very few make fortunes without actually delivering anything of value. G-WAN is technically better than all its competitors for this sole reason: for decades, treachery rules – and as a result the rich impostors are now very visibly technically miserable.
This is now increasingly obvious too all – not only in the field of Computer Science – and for more than 5 centuries (here in Europe):
They hold us Christians captive in our own country. They let us work in the sweat of our brow to earn money and property while they sit behind the stove, idle away the time, pass gas, and roast pears. They stuff themselves, guzzle, and live in luxury and ease from our hard-earned goods. With their accursed usury they hold us and our property captive. Moreover, they mock and deride us because we work and let them play the role of lazy squires at our expense and in our land. Thus they are our masters and we are their servants, with our property, our sweat, and our labor.
Not much has changed today, except that the same twisted system of deceptive and ruthless wealth extraction is now deployed globally:
I am afraid the ordinary citizen will not like to be told that the banks can and do create and destroy money.
The amount of money in existence varies only with the action of the banks in increasing or decreasing deposits
and bank purchases. We know how this is effected. Every loan, overdraft or bank purchase creates a deposit, and every repayment of a loan, overdraft or bank sale destroys a deposit.
If a very few private interests can create unlimited money, how long do you think it will take for them to replace everyone, in politics (government, army, police, science, education, infrastructures, etc.) and in the industry (funded by an ever-growing public debt)? And, once this is done, what will prevent them from granting themselves all public contracts, subsidies and... a total impunity?
They who control the credit of the nation direct the policy of Governments and hold in the hollow of their hands the destiny of the people.
When a government is dependent on the bankers for money, it is the bankers, not the government leaders, who control the situation, since the hand that gives is above the hand that receives. [...] Money has no homeland; financiers have no patriotism and no decency; their sole objective is gain.
War is the parent of armies; from these proceed debts and taxes...
known instruments for bringing the many under the domination of the few... No nation could
preserve its freedom in the midst of continual warfare.
We know now that Government by organized money is just as dangerous as Government by organized mob.
If the freedom of speech is taken away, then dumb and silent we may be led, like sheep to the slaughter.
Once again, schools, universities, Wikipedia and AI chatbots – all teach us one single very different story about "Democracy" and "Protestantism" than Martin Luther's 195-page book (warning, much shorter, rewritten versions are widely published): officially, in 1543, Martin Luther was supposedly opposing the Catholic church (for its indulgences, the ability for the Nobility to pay for their sins to be pardoned). But if you read Martin Luther's uncensored book (especially the second half) you will see that the real target of Protestantism, as illustrated by the above quote, was usury (the only reason why, 500 years later, still we suffer economic and intellectual decline, defective technologies and constant wars all over the Planet).
Once you have understood the root causes of this centuries-old problem, it is obvious that the robbers will not surrender their stolen powers to the people: they can only exist by relentlessly robbing our works and assets.
Yet, they are the very few, and their victims are the many – so there's no reason for the robbed and assassinated masses to accept this. We just have, individually and collectively, to say "No" – and build the world we want for our children. We don't want our world to be a paradise for the 0.01% and hell for the 99.99%, we want our world to be a paradise for the ones that respect their peers – and our world is what we, individually and collectively, contribute to build.
Be part of the changes that you want to see happening. Do every single little or big thing that you can do, like helping those in needs, making things easier for others when they are honest, and systematically closing the door to the serial abusers.
The interests of the 99.99% won't ever be promoted – unless we, the people, organize our society, the society we want. Locally, you can meet people face to face, but beyond a certain point, trustworthy communication tools are required – the kind that will not censor you, fail you at the worse moment, or shadow-ban you.
This is what I am building. Because I can. And every single product or technology I have made has demonstrated that today's chaos is artificially fabricated, planned, enforced – to prevent us from organizing ourselves to build an alternative.
Contribute to G-WAN by purchasing subscriptions, and I will do the rest.
Some among us have spent quite a lot of time and money at designing new ways to "dumb down" all others – to dominate and eradicate[ 1 , 2 ] them. They use disloyal means aiming to make all of us dependent on them rather than striving, so they provide things like "assistants" to:
- drive cars: then, you press buttons instead of interacting with the machine (learning to find the optimal way of doing things, which involves many of your skills). Pressing buttons deprives you from this understanding of how mechanical parts work together and you miss the opportunity to acquire and perform skills (while the IoT operator can, by the press of a button, send your car and its passengers to embrace a wall at full speed – in our troubled times, the ability to execute targeted or mass murders without a smoking gun has probably contributed to justify the gargantuan investments required to deploy Radio-controlled vehicles all over the Planet);
-
educate children: giving our kids to total strangers who are told by a central committee what they should know and what they should ignore certainly helps to explain the ever-falling quality of education seen in the countries where systematic bias, story-telling, History-rewriting and censorship are enforced by... the GAFAM funded (at our expenses) by our so-called "democratic" governments:
Artificial intelligence is of course different from nuclear fission in a host of ways. But it would be a grave error to assume that we shall use this new technology more for productive than for potentially destructive purposes. [...]
Individuals, nations, cultures, and faiths will need to determine the limits, if any, of Al's authority over truth. They will need to decide whether to allow AI to become an intermediary between humans and reality. [...]
Nations and international organizations, once they have coalesced around a consensus, must develop new political structures for monitoring, enforcement, and crisis response. -
replace 'too costly' employees: by a fake AI wich, at best, is a natural-language interface to privately-held search engines that are heavily subsided by our governments (that is us, the taxpayers – so we pay for our enslavement).
Worse: most of the data published nowadays is... purposely wrong (constant deceit has become the only remaining way to maintain financial growth): everybody knows that the official statistics (growth, inflation, unemployment, causes of mortality) are embellished to protect the guilty, and advance an agenda of systemic destruction of our society.
This erroneous data that AI will use to answer the questions asked by medical doctors seeking AI medical advice, the general public, the government (finance, army, justice, education, energy, industry, etc.), or even academic researchers:
It is simply no longer possible to believe much of the clinical research that is published, or to rely on the judgment of trusted physicians or authoritative medical guidelines. I take no pleasure in this conclusion, which I reached slowly and reluctantly over my two decades as an editor of the New England Journal of Medicine.
Call this "progress" if you can. This inability to replicate scientific studies has generated a "replicability crisis" that by far overwhelms the rare veterans that are still (1) employed, (2) competent and (3) honest. Can we trust governments and "Science" that spend more taxpayer money than ever printed in History – to deploy this fake private AI (while they hastily remove the remaining competent people from the workplace) so that they can no longer be proven wrong?
The mass regurgitation of misinformation done by AI generates ever-growing losses in skills, GDP and future outcomes. And if our financial and political leaders are happy with that, then we should fire them before we all disappear from the equation. - program computers: like for autonomous cars, programming languages that provide a function for every possible needs may look handy (the only skill you need is to find the function name in an humongous collection of press-button libraries) – but that's also the most certain way to limit what you can actually do (in terms of ease of use, performance, security, and features) since all creativity is excluded by-design. As G-WAN and SLIMalloc illustrate it, there's a gigantic gap between what is possible (and desirable) and the false, complex theories that are taught by the best universities and made by... the GAFAM.
In the same vein, AI chatbots cause cognitive offloading as AI users relying on the technology for problem-solving and decision-making rather than engaging in independent critical thinking. This leads to skill erosion as people no longer exercise their own capacity and can't diverge from the "ready to use" opinions delivered by the AI operators, leading to an ever-growing dependence on AI tools and an ever-disappearing expertise and judgment.
And here I did not even touch the "sweet pot" of these bandits: when "experts", government officials, teachers, the media, judges and attorneys, or engineers rely on these tools without verifying the accuracy of what they produce (why use AI if you have to check the facts independently, right?), they become the unsuspecting victims of manipulation:
- Unverified data: AI tools often generate plausible but incorrect outputs, and this has been massively seen in legal proceedings and scientific papers where fabricated evidence or inaccurate calculations were introduced by the AI "assistants" (belonging to private companies that may sell this ability to influence or betray, on a per-case basis or on mass-scales, punctually, or constantly).
- Erosion of expertise: outsourcing complex tasks to AI erodes the increasingly-unexercised skills needed to critically evaluate or challenge evidence, leading "experts" to become mere parrots of an AI itself programmed by a private company.
- Unaccountability: blind trust in an AI falsely presented as "knowing better" shifts responsibility away from its users, creating a dangerous precedent where errors (caused by AI operators that will revert to blaming their creation to avoid being jailed) are overlooked or dismissed – even in the case of outright fraud!
- The ultimate transfer of property: to pay back today's unpayable debt they are assigning the management of all natural resources to a very few among us: since 2021, NYSE Natural Asset Companies (NACs) are valuing natural assets (food, fresh air, drinkable water, good soil, plant and wildlife) to... monetize them. A Nature that was free for all since the beginning of times will be sold by a very few AI operators to the rest of the Planet for... 4 quadrillion US dollars. "Creative accounting" and "financial Darwinism" at their best: survival will depend on your ability to pay for vital resources that have been free for 4 billion years (Planet Earth's age).
Of course, it is, once again, a pure coincidence that the AI bubble has now been officially proven to be a fraud generously funded by the taxpayer (via even more public debt) – remember the $5T spent to "build new datacenters" (despite not enough water and energy to do so), an amount of money 16 times larger larger than... the combined (fake) Manhattan Project (1942-1946) and (fake) Apollo NASA Program (1961-1972).
Why "fake"? The above second video (Apollo documentary) allows to understand what's wrong with the first, 4-second video (Manhattan demonstration).
Tip: nuclear explosions generate gamma rays and an EMP pulse. Both travel at the speed of light, disabling cameras, argentic films, radio transmissions and devices BEFORE the blast and shock wave filmed here. Worse, instead of being blown away in one direction by a remote explosion, the house parts are flying away in all directions... like the smoke or dust originating from within the house and slowing-down as it expands – before the film is cut. Only an explosion taking place from within the house can cause this. I do not claim that nuclear weapons do not exists. I just claim that some official videos are fake, especially when they tell a story aimed at impressing the masses to raise trillions of US dollars from the taxpayer (public debt, pension funds, etc.).
These gargantuan, unproductive expenses (infinitely enriching entrenched robbers) are funded via public debt, with interests paid back by taxpayers (the principal is never paid back). This is an old secret tactic, so valuable for some that when they feel the need to comment it, they (a recurring scheme) focus on the remote consequences rather than on the primary causes: "The Coming Storm", a new book, explains how kings and emperors that were cousins and friends since their childhood have started WWI.
Yet it never tells that (1) wars (that is, robbing your neighbors) are the only way to pay back gigantic financial debt, and (2) wars are impossible without unprecedented funding (even more debt, paid back by all countries' taxpayers, and granted to all the involved countries by one single private banker), and that (3) the cumulated debts of wars are all paid back (to the private banker) by the winners at the expense of the losers.
As a bonus, the casualties on both camps leave many unclaimed assets available for Finance – easy growth, by mass killings, that's why so many modern wars target defenseless civilians. So each war increases the power of the banker, and decreases the power of the nations that, strangely, have forgotten that the monetary creation was created and has existed for thousands of years as a State privilege, before mysteriously becoming a private business... now globally commanding to all States.
Hiding our History and how we have been enslaved can certainly help to explain why some have recently felt the urge to write: "Individuals, nations, cultures, and faiths will need to determine the limits, if any, of Al's authority over truth. They will need to decide whether to allow AI to become an intermediary between humans and reality."
Robbers and liars rarely enjoy being exposed: it increases their risk to face sanctions, depriving them from the bounty stolen from the masses. So, in an era of ubiquitous, instantaneous data exchange via the Web, the only way to censor and rewrite History in real-time is this... fake AI (private search engines reachable via a natural language interface).
I am sure that there will be people claiming that all of these (unprecedented in History) coordinated acts are "benign, accidental mistakes" – but, even at the relatively modest Internet servers marker level, I hardly see why and how wrk2 crashing at 10k+ users was a necessary feature for a multicore benchmark tool so unanimously considered and celebrated as the "best of its class"... despite 4 unpardonable multi-threading programming bugs – all defeating its official purpose.
Worse: while working on G-bench, the benchmark tool integrated in G-WAN, I have found that ALL the other benchmark tools avoid to disclose more important information than... the latencies and RPS!
Once again, the toxic tactic is constant: millions of 'experts' sing the same song for decades "look here! (so that you won't ever look there)". That's the difference between information (detached from the insights that would let you decide if it's true or false) and knowledge (experiencing the reasoning that leads to the information).
I knew this problem could happen, but, lacking a measurement tool disclosing its scale, I never imagined that it could be in such massive amounts. And, even more revealing, the NGINX team has explicitly and repeatedly claimed that this problem was resolved by NGINX and the event queues... while (unsurprisingly?) the exact opposite was true: as G-WAN demonstrates it, both aggravate this crucial issue!
Given the vital importance of this self-censored metric, this generalized "Omertà" of ALL the benchmark tools made so far is indisputably not accidental. This is done on purpose to hide a very inconvenient truth that is much more shocking than anything found in the current blog post.
The only way to show that you are right is to do much better than everyone else. G-bench will restore the defaced status of "Computer Science" by publicly providing the information that has been hidden, by all private and public experts, at the expenses of all BigTech end-users, for 25 years – helping to explain why G-WAN, for having done so much better since 2009 (also with this issue), has been censored for 18 years!
If there's no outright financial, scientific and industrial fraud here, I can't understand why it is so difficult to find a reasonably designed, performing and reliable benchmark tool for servers: all other tools, including the most recent made in Go and Rust, are even slower and less capable than wrk2... so ever-degrading quality and spiraling budgets are presented as "the unescapable march of progress"! Cui bono? Follow the money!
I have called wrk3 this fixed version of wrk2 (without the bogus RPS due to 4 by-design concurrency programming flaws) that doesn't crash at 10k users (download it here). It's also easier to compile: (1) it comes with its dependencies and (2) has a Makefile using them.
wrk3 gives "exact numbers" (that is, artifically slow due to its by-design bottlenecks, but far less volatile and inflated than wrk2 and wrk): G-WAN now tops at 3.4m RPS at 10k users and 15m RPS at 40k users on the same machine where the same (relatively old) version of G-WAN topped at 281m RPS at 10k users and 63m RPS at 40k users... with the original (now known as faulty) wrk2 (and 500+m RPS with NGINX's wrk) – the very same benchmark tools published (without examination?) by the main Linux distributions, countless "scalability experts" and many hosting web sites.
But, even with the slow wrk3 test, G-WAN wins the 10s + 30s + 3m + 30m benchmarks (the sprints, middle range races and marathons) – and it keeps improving:
G-WAN Apr 2026 -------------- 1: 223k RPS │ To appreciate these numbers, keep in mind that 10: 1.4m RPS │ on the same machine NGINX tops at 1m RPS with 1k users 1k: 2.4m RPS │ before declining. 10k: 15.5m RPS │ 20k: 34.4m RPS │
Even better, instead of the G-WAN performance drop after 10k users (wrongly) reported by wrk2, now wrk3 (rightly) shows that G-WAN performance NEVER drops (G-WAN RPS grow with the number of users, which is not the case for NGINX after 1k users).
The most recent G-WAN version is now even faster than the April 2026 version (very badly) tested here by wrk3, but that will be for another blog post, where we will compare G-WAN server benchmarks made by wrk3 and G-bench, the benchmark tool integrated in G-WAN, wrk/wrk2 being much too broken to produce useful benchmarks (that was most probably their sole purpose).
I share wrk3 to let people test their own works and G-WAN... because we all deserve better tools than the ones provided by the best-funded and well-promoted "experts" of this "big-tech" industry. Wake-up, small is beautiful (and reliable, maybe because it can't afford to buy favorable media, political, fiscal, legal and judicial exposure).